
IndexTTS 是 B站推出的最新文本转语音(TTS)模型,它能够使用拼音纠正汉字的发音,并通过标点符号在任何位置控制停顿。在中文场景下,它展现了卓越的表现,并刷新了行业记录。IndexTTS 通过中文字符-拼音混合建模、精准停顿控制与跨模态优化等先进技术,显著提升了语音生成的精度和自然度。
强大的技术和性能
IndexTTS 系统经过数万小时的数据训练,已实现业内领先的性能,超越了当前流行的 TTS 系统,如 XTTS、CosyVoice2、Fish-Speech 和 F5-TTS 等。系统的多个模块经过增强,特别是在扬声器条件特征表示和音频质量优化方面进行了深度改进。通过引入混合建模的方式,IndexTTS 能够快速纠正误读的汉字,提升了用户的使用体验。
最新版本带来的提升
今天分享的 V3 版本,更新了更强大的 IndexTTS-1.5 模型,显著提高了模型的稳定性和英语语言性能。这个版本不仅在中文语音生成方面表现出色,还拓展了对多语言的支持,使应用场景更加广泛。
应用场景
IndexTTS 的成功在于对中文语言特性的深刻理解和创新应用,适用于需要高精度和自然度语音生成的场景,如教育、娱乐、新闻播报等。其精准的停顿控制和多音字处理能力使其在中文朗读和语音合成领域具有显著优势。
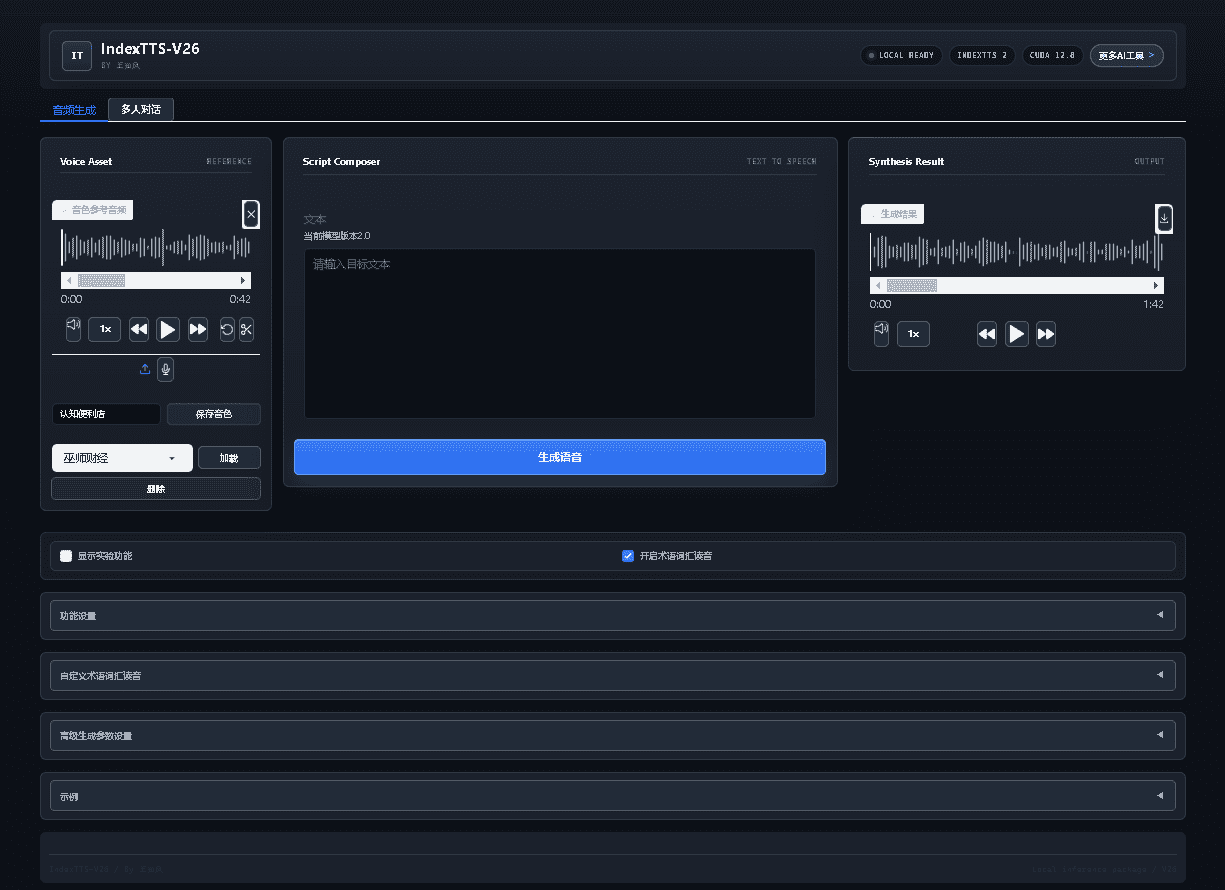
使用教程
IndexTTS 使用教程如下,建议使用 N 卡,显存 4G 起,支持 50 系显卡,基于 CUDA 12.8。
步骤 1:上传参考音频
上传参考音频以帮助模型更好地生成语音。
步骤 2:输入文本
在文本输入框中输入需要转换为语音的文本内容。
步骤 3:生成语音
根据文本长度选择“普通推理”和“批次推理”。实测“批次推理”充分利用显存,生成速度提升 10 倍以上,但稳定性略逊于“普通推理”。大家可以根据需要自行调整。
免责声明:本站所有资源均收集自互联网,分享目的仅供学习参考,并不贩卖资源,资源版权归该资源的合法拥有者所有,请您在下载后24小时内删除。若本站发布的内容侵犯到您的合法权益,请立即联系43404810@qq.com及时做删除处理!

